Myers算法探究
Myers算法探究
前言
最近在尝试梳理androidx包下的ListAdapter源码,理解其是如何快速找出新旧两个列表中不同处。在此过程中发现一处非常难以理解且繁琐的代码块,经查询后得知是运用了Myers比较算法,同时该比较代码也在Git diff中有过大展身手。因此想仔细研究下该算法思想。拖了几周,终于开工进行梳理。
简介
Myers Diff算法到底解决了什么问题?
引入: 比较两个字符串之间转换最短路径问题
具体: 能够从算法层面揭示两个文件间的差异
引入
如何比较两个文件的差异?
每次修改文件时,文件系统File System是不会为我们统计到每一行是否更改的,其关注点仅仅是整个文件的层面(否则将占用较多的额外空间)。例如其关注文件内容A最终变为内容B, 但不会统计文件内容A如何转化为B。因此我们其实无法准确知道自己当时实际修改了哪些行,仅仅知道该文件于几时更新,更新后是什么样的。对于行的比较,可以简化理解为是基于字符串的比较,因此,可以将问题简化为分析如何比较两个字符串的差异。
如何比较两个字符串的差异?
概念梳理
对于字符串,我们需要先理清楚一些概念, 或许暂时用不到, 但先有个印象
概念理清
- Input: 字符串A为输入字符串、字符串B为待转化字符串们,A需要通过一组特定的指令来转换为B
- SES: Shortest Edit Script, 算法通过找到将A转化为B的最短编辑脚本(可理解为所需指令数量最少),在该条件下,指令包括以下两种
- 从A中顺序删除一个字符
- 从B中顺序添加一个字符
- LCS: Longest Common Subsequence(最长公共子序列), 一个数列S,如果分别是两个或多个已知数列的子序列,且是所有符合此条件序列中最长的,则S称为已知序列的最长公共子序列 (自己最初对这个概念不太清楚, 容易与最长公共子串概念混淆)
一种变换多种解读
对于以下更改,我们可以有不同的解读。
原文件: A B C A B B A
修改后: C B A B A C
# 全量删除, 删除在前
-A -B -C -A -B -B -A +C +B +A +B +A +C
# 全量删除, 删除在后
+C +B +A +B +A +C -A -B -C -A -B -B -A
# 以A串为主, 先进行修改
-A -B C -A B -B A +B +A +C
# 符合一般习惯
-A -B C -A B +A B -A +A +C
通过上述四种不同的分析,可以看到新老文件的修改可有多种解读方式。但哪一种更好,更符合人们一般常识呢
通常我们习惯:
- 差异应该表现为更连续的增加或删减, 对应代码为一部分一部分的更改。
- 相同的内容应该尽可能多, 即差异要尽可能小
- 更愿意看到删减而不是新增 (约定)
Git是如何实现新老版本文件比较的?
在使用Git时,通过git diff命令,我们能快速知晓当前未提交的修改与已入库版本的区别。
例如在git仓库下创建一个文件, 包含ABCABBA(每个字符后进行换行), 进行提交后,将原文件修改为CBABAC(每个字符后换行),此时使用git diff命令,会发现有如下结果
diff --git a/a.txt b/a.txt
index d8a1b05..5db0ef8 100644
--- a/a.txt
+++ b/a.txt
@@ -1,7 +1,6 @@
-A
-B
C
-A
B
+A
B
-A
\ No newline at end of file
+A
+C
\ No newline at end of file
(END)
VsCode上查看commit差异表现如下
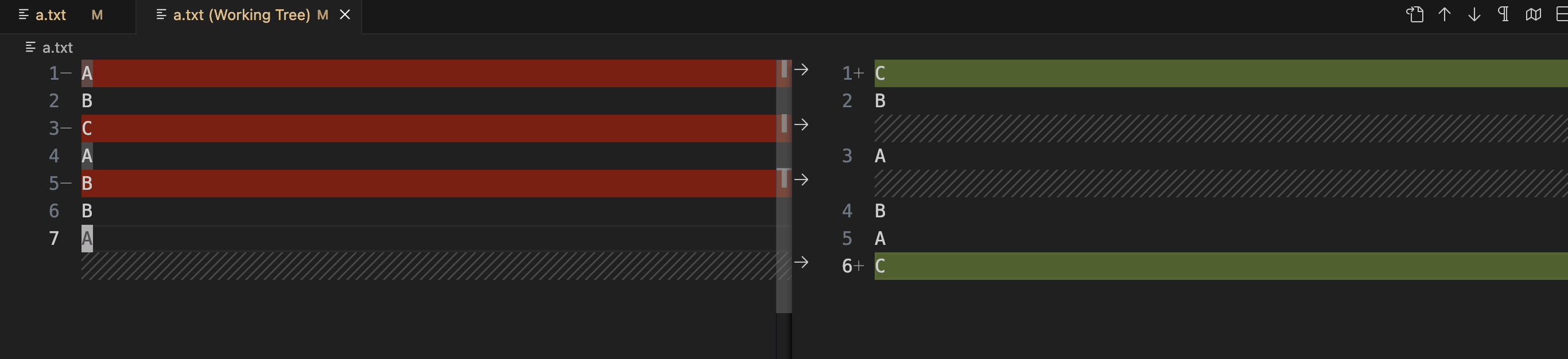
是不是与我们预期的修改预测一致呢?那Git是如何做到的呢?
git diff内置四种算法,包括myers(默认)、minimal(尽力找出最小差异)、patience、histogram,如下图所示
Introduction
📖 Git - diff-options Documentation
--diff-algorithm={patience|minimal|histogram|myers}
Choose a diff algorithm. The variants are as follows:
default,myersThe basic greedy diff algorithm. Currently, this is the default.
minimalSpend extra time to make sure the smallest possible diff is produced.
patienceUse "patience diff" algorithm when generating patches.
histogramThis algorithm extends the patience algorithm to "support low-occurrence common elements".
For instance, if you configured diff.algorithm variable to a non-default value and want to use the default one, then you have to use --diff-algorithm=default option.
可以看到其默认是通过myers算法进行差异计算的,那这就引入到我们的主题啦
推理
规则定义
如何将一个字符串A转化到一个字符串B? 理解该过程一定要结合文件改变的角度。
首先我们希望变动尽量少、尽量集中,因此就需要考虑从A转换到B的代价问题,同时已知的最小变动类型为: 删去、新增以及维持不变,维持不变不需要开销,而删去、新增一个字符的开销都假设为1, 即拥有相同的开销权重。要想得到理想的变换推理,需要根据以下逻辑:
- 当能维持不变时,优先维持不变
- 优先看通过删除操作能否实现变换
- 采用花销数最小的方案
以比较出名的例子:字符串A(A B C A B B A) 字符串B(C B A B A C)为例,按照以下方式排出图标:
- 横轴为A字符串, 纵轴为B字符串
- 向右移动一格即代表 删除箭头处字符,向下移动一格即代表 添加箭头处字符
- 单个具有实际消耗性质的改变称为一步,向右或向前均需要一步。
- 当当前位置的下一步横坐标字符与纵坐标字符相等时,可以沿对角线移动,且优先采用该种方案, 且不产生步数(代表维持不变的实际含义)
- 优先考虑向右走(人为规定删除在先)
- 最终走到右下角末尾点即表明转化完成
核心思想类似于贪心 + 指针式的遍历,以字符串A为原串,字符间的间距作为索引元素(类似于我们在输入框中输入字符时会显示的细细的竖状指针 |), 从0开始基于新串对原串进行上述的三种操作,使其最终转换为新串
手动模拟
尝试用上述例子手撸一次流程,假设我们是计算机,只能进行单步操作,则如何能得到正确结果呢?
第一步
原字符串为 ABCABBA
- 尝试删除A字符 --> |BCABBA (|之前的字符串表明已验证,与C串前缀一致,|之后的字符串表明未验证,属于串A并还未验证的部分)
- 尝试添加C字符 --> C|ABCABBA
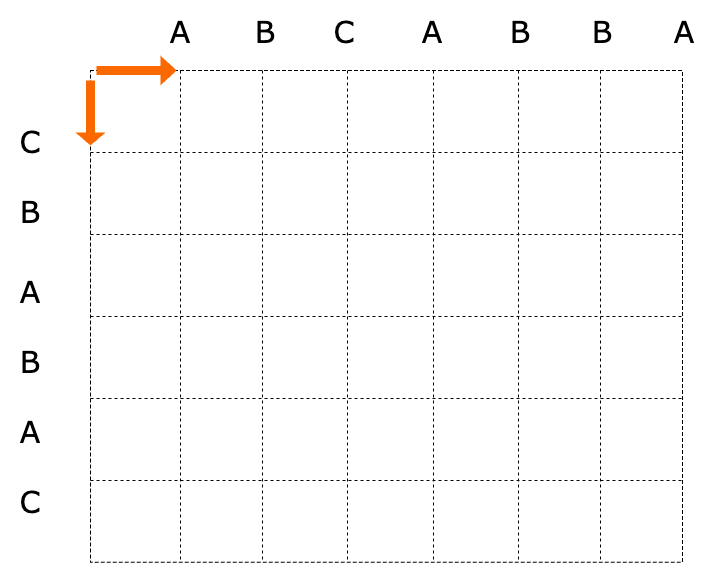
第二步
- |BCABBA
- 尝试删除B字符 --> |CABBA --> 对角线匹配 --> C|ABBA
- 尝试添加C字符 --> |CBCABBA --> 对角线匹配 --> C|BCABBA
- C‘ABCABBA
- 尝试删除A字符 --> C|BCABBA --> 对角线匹配 --> CB|CABBA
- 尝试添加B字符 --> CB|ABCABBA --> 对角线匹配 --> CBA|BCABBA --> CBAB|CABBA
.png)
第三步
与上述流程类似, 请自行推测
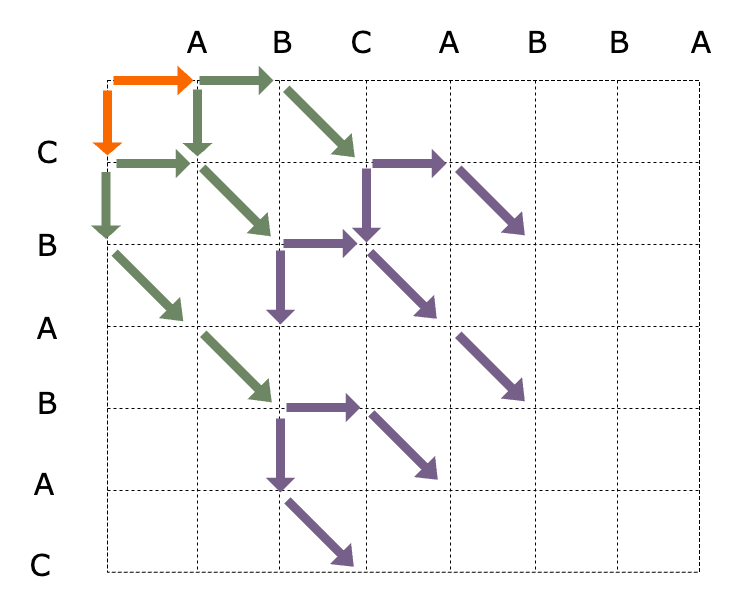
第四步
与上述流程类似, 请自行推测

第五步
与上述流程类似, 请自行推测

总结
总结下,其核心思想类似于贪心 + 指针式的遍历,以字符串A为原串,字符间的间距作为索引元素(类似于我们在输入框中输入字符时会显示的细细的竖状指针 |), 从0开始基于新串对原串进行上述的三种操作,使其最终转换为新串
思考
为什么这里考虑了走对角线就不考虑下一步在这之前不走对角线呢?
K线
这里将k-线定义为 k = x - y 的直线,则可以表示为以下形式
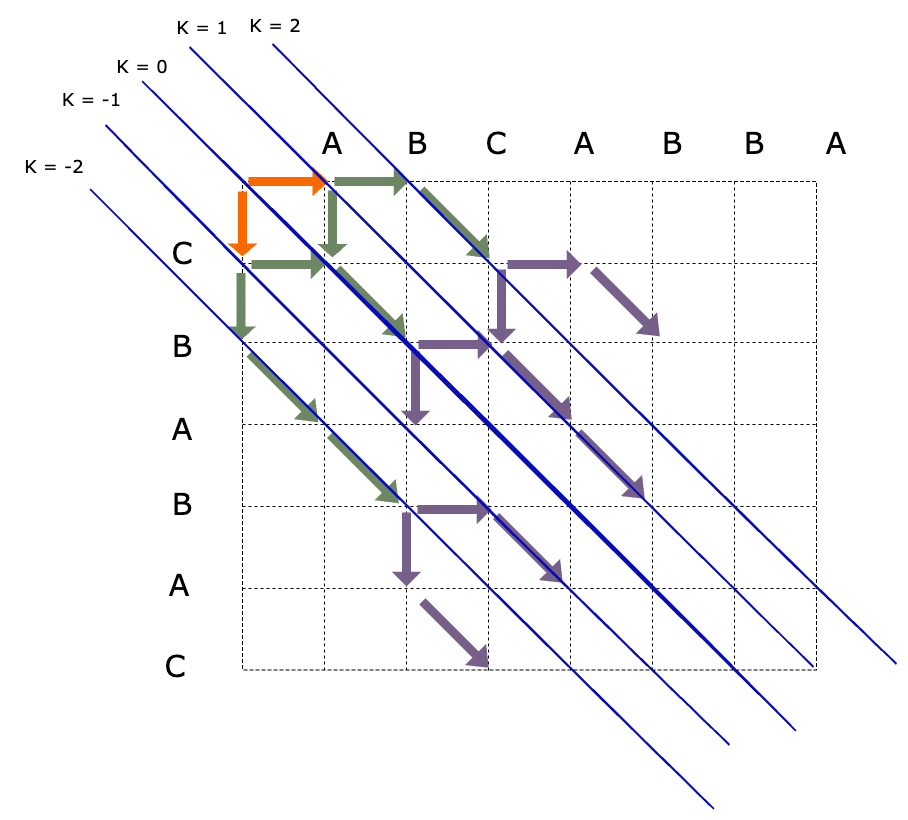
引入K-线对理解Myers算法有何帮助?
用相邻K线提前限制了一步的范围
举个例子, 例如从所在k线的(x, y)点出发, 由于只能向右或向下进发, 也下一步所在的k线只能为k + 1 或 k - 1的k线上,因此通过这种方式,就可以将原本走一步有许多不确定取值的点锁定为点一定在两条线之一的情况。
关于K-线的定理
- 对步长为D的路径, 其终点所在K线的取值范围一定在以下区间, 即 $ K \in { -D, \ -(D-2), \ \dots, \ 0, \dots , \ D-2, \ D } $
- 偶数步长的路径落在偶数K线上, 奇数步长的路径落在奇数K线上
- 对于点在K线上的一点,其上一步只能通过以下两种方式的一种到达:
- 从K+1线上的点下移一步到达
- 从K-1线上的点右移一步到达
思路
因此可基于贪婪算法, 有以下模拟
对每一步的所有情况进行判断,查看其在所有可能的K-线的移动情况,判断其是否能够到达终点, 并统计每一步各K线的最远点
- 对步数为D的点,若当前所处K-线值为K
- 判断其上一步的点(最后落点)是如何移动到该点的(下移 / 右移)
- 推出上一点的K线, 通过统计的各k线历史最远点推出上一步点的坐标
- 推出该点的坐标
- 判断该点是否还可沿对角线移动
- 统计该K线上点到达的最远点
- 判断是否到达终点,是则推出,否则循环
代码
由以上分析,有以下代码
路径搜寻
首先需要找到一条能满足上述条件的路径
/**
* 找到从A-> B串转化所需要最小步数的转换路径
* @param a 原串
* @param b 新串
* @return 每一步中所有K线到达的最远X坐标点的哈希表
*/
fun findMinStepPath(a: String, b: String): List<Map<Int, Int>> {
// 最多需要走多少步
val maxStep = a.length + b.length
// 存储当前k线能到达的最远x值
val v = mutableMapOf<Int, Int>()
// 保存每一步最终每条K线能到达的最远x值
val list = mutableListOf<Map<Int, Int>>()
list.add(mapOf(Pair(0, 0)))
// 贪心算法, 顺序地看每一步的过程
outerLoop@for (d in 1..maxStep) {
// 当前步数下每条K线能到达的最远x值
val tempV = mutableMapOf<Int, Int>()
// 遍历当前步数下所有可能的k线点的情况
for (k in -d..d step 2) {
/*
* 重要条件: 针对当前步数、当前K线上的点, 上一个点是通过哪种操作移动到该点的(只能是右移或下移)
* 1. 特殊情况--下移: 当前点所在k线已经是-d(由公式限制条件可推出, 由上一个点从k-1线向下移动得来)
* 2. 特殊情况--上移: 当前点所在k线已经是d(由公式限制条件可推出, 由上一个点从k-1线向右移动得来)
* 3. 一般情况:
* 1. 下移: k+1线能到达点的最远x值大于k-1线(可以理解为k+1线的路径删除了更多的字符, 是人们期望看到的结果)
* 2. 上移: 反之
*/
val isDown = k == -d || k != d && v.getOrDefault(k + 1, 0 ) > v.getOrDefault(k - 1, 0)
// 推出上一步坐标所在的k线以及坐标
val prevK = if (isDown) k + 1 else k - 1
val prevX = v.getOrDefault(prevK, 0)
// 通过上一步k线和坐标推出这一步坐标
var x = if (isDown) prevX else prevX + 1
// 判断是否还能走对角线
while (x < a.length && x - k < b.length && a[x] == b[x - k]) {
x++
}
// 统计该步数下该K线能到达的最远坐标点
v[k] = x
tempV[k] = x
// 如果匹配完成, 即达到右下角端点, 则退出
if (x == a.length && x - k == b.length) {
list.add(tempV)
break@outerLoop
}
}
// 保存每一步下每条K线的最远点
list.add(tempV)
}
return list
}
路径回溯
先理解下回溯需要用到的数据结构
data class Point(
val x: Int,
val y: Int
) {
override fun toString(): String {
return "Point(x=$x, y=$y)"
}
}
data class Snake(
val startPoint: Point,
val midPoint: Point?,
val endPoint: Point,
val isDown: Boolean
) {
override fun toString(): String {
return "Snake(startPoint=$startPoint, isDown=${if(isDown) "|" else "->" } midPoint=$midPoint, endPoint=$endPoint)"
}
}
理解Snake
Snake即代表每一步路径的简化表示, 包含Start Point -- Mid Point -- End Point三点坐标,来指明该步所经过的路径
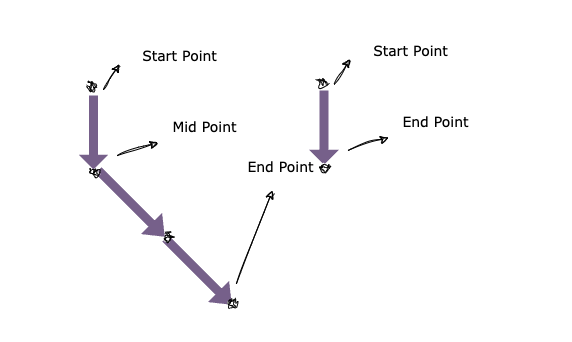
具体回溯代码:
/**
* 回溯推出原串到新串的原路径
* @param a 原串
* @param b 新串
* @param list 每一步中所有K线到达的最远X坐标点的哈希表
* @return 包含每一步移动信息的列表
*/
fun trackPathBack(a: String, b: String, list: List<Map<Int, Int>>): Deque<Snake> {
var currentX = a.length
var currentY = b.length
// 实际list包含了第0步的k线路径, 因此需要-1
var currentD = list.size - 1
val snakes = LinkedList<Snake>()
/*
* 如果当前点是第五步得到, 则需要回退到第四步时K线-X坐标情况进行判断
* 判断上一点当时是通过何种操作移动到该点的(可以理解为场景还原)
*/
// 理解这里先进行自减
while (--currentD >= 0) {
// 计算出该点所在的K线
val k = currentX - currentY
val startX = currentX
val startY = currentY
val v = list[currentD]
// 场景复现
val isDown = k == -currentD || k != currentD && v.getOrDefault(k + 1, 0 ) > v.getOrDefault(k - 1, 0)
// 推出上一步坐标所在的k线以及坐标
val prevK = if (isDown) k + 1 else k - 1
val prevStartX = v.getOrDefault(prevK, 0)
val prevStartY = prevStartX - prevK
// 推出中间坐标(即对角线前的坐标, 不走对角线则无中间坐标)
val midX = if (isDown) prevStartX else prevStartX + 1
val midY = midX - k
currentX = prevStartX
currentY = prevStartY
// 入栈
snakes.push(
Snake(
Point(currentX, currentY),
if (midX != startX || midY != startY) Point(midX, midY) else null,
Point(startX, startY),
isDown
)
)
}
return snakes
}
应用
有了每一步所经历的路径, 则能够很简单地推出A串到B串到转化过程
/**
* 获取类似Git类的增减变化提示
*/
fun getDiffTextBySnakes(a: String, b: String, snakes: Deque<Snake>): String {
var x = 0
var y = 0
val res = StringBuilder()
while(snakes.isNotEmpty()) {
val snake = snakes.pop()
println(snake.toString())
val str: String
if (snake.isDown) {
// 增加新串的字符
str = "+${b[y++]} "
} else {
// 删去原串的字符
str = "-${a[x++]} "
}
res.append(str)
// 若经过了对角线, 则表示有部分字符保持不变, 需要进行额外处理
if (snake.midPoint != null) {
var diff = snake.endPoint.x - snake.midPoint.x
while(diff-- > 0) {
res.append("${a[x++]} ")
// 注意y也需要自增
y++
}
}
}
return res.toString()
}
对以上方法, 有以下调用:
fun main() {
val a = "ABCABBA"
val b = "CBABAC"
val list = MyersAlgo.findMinStepPath("ABCABBA", "CBABAC")
val snakes = MyersAlgo.trackPathBack(a, b, list)
val diffStr = MyersAlgo.getDiffTextBySnakes(a, b, snakes)
println(diffStr)
}
有以下结果:
Snake(startPoint=Point(x=0, y=0), isDown=-> midPoint=null, endPoint=Point(x=1, y=0))
Snake(startPoint=Point(x=1, y=0), isDown=-> midPoint=Point(x=2, y=0), endPoint=Point(x=3, y=1))
Snake(startPoint=Point(x=3, y=1), isDown=| midPoint=Point(x=3, y=2), endPoint=Point(x=5, y=4))
Snake(startPoint=Point(x=5, y=4), isDown=-> midPoint=Point(x=6, y=4), endPoint=Point(x=7, y=5))
Snake(startPoint=Point(x=7, y=5), isDown=| midPoint=null, endPoint=Point(x=7, y=6))
-A -B C +B A B -B A +C