Java学习
Java SE
集合
ArrayList
- 允许添加多个null值
- 属性 size 是指 elementData 中实际有多少个元素,而 elementData.length 为集合容量
- DEFAULTCAPACITY_EMPTY_ELEMENTDATA和EMPTY_ELEMENTDATA区别: 构造函数 是否有initialCapacity
- 第一次添加元素时扩容 默认初始的集合容量 10
- grow(): 数组扩容策略,1.5倍且与最小容量进行比较
- 每次增删都使modCount增加 ,并且增删会进行modCount的检查,例如在迭代时进行增删操作时 会报错,Itr中的expectedModCount与modCount不一致!因此ArrayList是不支持多线程的
标记-清除法
HashMap
内部hash函数
put前要进行对再次对hashcode再次hash,也就是高16 和低 16做异或运算:增大散列程度。高位特征不变,低位也具有高位特征。避免容量小时key的高位不参与运算问题
‘>>>’无符号右移
为什么要重写equals 和hascode方法 ,puVal方法中有提到
注意区分Node的hash 和 key的hashcode
基本类型的hashcode方法
自动装箱 最硬核的居然是Integer的hashcode方法,居然就返回的value!!
为什么要右移16位?
减少碰撞 降低hash冲突
JDK 1.8 put
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //重点关注 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; //重点关注 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //这句话允许了配的钥匙可以开相同的锁 e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }resize扩容机制
JDK 1.6
void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }注意 & oldCap 和 &oldCap-1 的区别!!!
注意这里的 (e.hash & oldCap) == 0
Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab;首先将高16位无符号右移16位与低十六位做异或运算。如果不这样做,而是直接做&运算那么高十六位所代表的部分特征就可能被丢失 将高十六位无符号右移之后与低十六位做异或运算使得高十六位的特征与低十六位的特征进行了混合得到的新的数值中就高位与低位的信息都被保留了 ,而在这里采用异或运算而不采用& ,| 运算的原因是 异或运算能更好的保留各部分的特征,如果采用&运算计算出来的值会向1靠拢,采用|运算计算出来的值会向0靠拢
Node 单链表结构
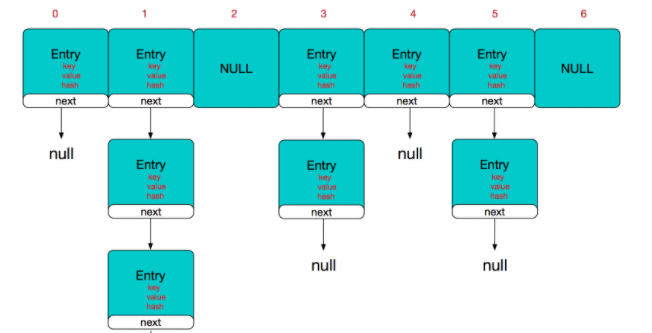
image-20210228192712917 扩容机制
hash碰撞
发生hash碰撞时 当前的元素生成新的节点保存在链表的尾部
HM的线程安全方式
- Collections.synchronizedMap()返回一个新的Map:使用synchronized进行互斥。使用代理模式new了一个新的🥱,直接锁住方法
- ConccurentHashMap:使用新的锁机制,将HM进行拆分。
HM JDK1.8后扩容上的优化
- 1.7之前:重新hash计算
- 1.8:只比较扩容后最高位, resize时索引增加到oldSize位即可
线程不安全造成了什么问题?
产生环形链表
LinkedHashMap
结构
accessOrder有什么用?
transient关键字不可见 ?字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
实现LRU
插入删除原理
hashmap留的后门
哪种情况下get也会使得重新排序
ConcurrentHashMap
JDK1.8中以CAS与synchronized 锁头节点方式实现线程安全,锁的粒度更细
优先选择-- 性能效率更高
能说说什么是快速失败什么是安全失败吗?
快速失败 modCount 不能在多线程下并发修改
安全失败 concurrent包下的容器都是
SynchronizedMap
排斥所 Object mutex
就是加锁
HashSet
Hashset底层由什么实现?
hashmap
PriorityQueue
数组组成;modCount禁止并发
基于堆的排序
Clone
User u1 = new User(...);
User u2 = u1;//将u1的reference给了u2
u1 != u2
Obj obj = new Obj();
obj = new Obj();
obj.stu = new Stu();
Obj obj2 = (Obj) obj.clone();
System.out.println(obj2==obj);
System.out.println(obj2.stu == obj.stu);
System.out.println();
此时操作u2/u1 都会使另一个的值发生改变
但如果我们不想改变另一个的值就需要使用到clone
实现Cloneable接口 //Cloneable接口没有具体的实现方法,他相当于是一个标识,如果类没有继承cloneable接口而调用clone方法,会抛出CloneNotSupportedExcepion异常
深拷贝和浅拷贝
浅拷贝
clone无法clone 一个对象中的另一个对象,还是是一个reference
深拷贝
在对象的对象中实现cloneable接口,重写clone方法
@Override
protected Object clone() throws CloneNotSupportedException {
Obj obj = (Obj) super.clone();
obj.stu = (Stu) stu.clone();
return obj;
}
clone的保护机制
object类中有protected 的native方法 clone,且 User肯定是继承了Object,为什么
未实现Cloneable接口的类不能调用clone方法
延伸: protected的作用范围
一个public 类, 有protected的方法,
如果在同包下新建类继承他,这个新建的类对象能够调用protecTed的方法
如果在不同包下 新建一个类 继承他, 创建这个类的对象,不能调用 clone方法,但是可以在这个类中重写protected的方法,这样就能够调用。
这就是protected的 派生类对同包可见,不同包不可见的原理
protected受访问保护规则是很微妙的。虽然protected域对所有子类都可见。但是有一点很重要,子类只能在自己的作用范围内访问自己继承的那个父类protected域,而无法到访问别的子类(同父类的亲兄弟)所继承的protected域和父类对象的protected域
- public:表明该成员变量或者方法对所有类的对象都是可见的,所有类的对象都可以直接访问
- private:表明该成员变量或者方法是私有的,只有当前类对其具有访问权限,除此之外的其他类或者对象都没有访问权限。
- protected:表明该成员变量或者方法对该类自身,与它在同一个包中的其他类,在其他包中的子类都可见。
- default:表明该成员变量或者方法只有自己和与其位于同一包内的类可见。若父类和子类位于同一个包内,则子类对父类的default成员变量或者方法都有访问权限;若父类和子类不在同一个包内,则没有访问权限。
关键字Final
关于final的问题,推荐阅读《Java并发编程的艺术》☕
Final修饰类或方法
一个类被final定义时,表示该类不打算被继承,final类中的任何方法都隐式为final,无法覆盖。在字节码层面,final修饰的普通方法会多有一个flag: ACC_FINAL
注意:
- final方法可以被重载,不能被重写
- private方法是隐式的final
Final修饰常量
Final的延迟声明,需要注意的是,如果实现了blank final以及final的延迟赋值,那在其所有的构造器方法中都要实现final常量的赋值
final int x;
public Test() {
x = 1;
}
所有被final修饰的字段都是编译期常量吗?
并不是,比如 final int x = new Random().nextInt();就不是编译期常量
static final字段表示什么?
表示占据一段不能改变的存储空间,必须在定义的时候进行赋值,否则将不通过编译。但是实际赋值过程可以在非编译期
域重排序规则
关于重排序的知识,在*《JVM学习---JVM内存模型JMM》*章节中有详细讲到
多线程下
写final域重排序规则(final为基本变量)
禁止对final域对写重排序到构造函数之外,编译器在final域写之后,构造函数return之前,会插入storestore屏障,禁止处理器把final域到写重排序到构造函数之外,考虑以下一个场景:
class T{
int a;
final int b;
public T() {
b= 2;
a= 1;
}
static void init() {
t = new T();
}
static void read() {
T x= t;
int a = x.a;
int b = x.b;
}
}
两个线程进行操作,已知重排序可能会把普通变量重排序到构造函数之后(未验证),如果没有进行加锁操作,一个线程执行init方法,一个线程执行read方法,恰巧这时候init线程刚初始化了t对象,构造函数执行完毕将引用赋值给变量t,另一个线程拿到引用地址,读取普通变量,这时候a可能未被赋值,为0值。
而使用final修饰的变量可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确地初始化过了,而普通域无法保证。
读final域重排序规则(final为基本变量)
在一个线程中,初次读对象引用和初次读该对象包含的final域,JMM 会禁止这两个操作的重排序,处理器在读final域操作之前插入一个LoadLoad屏障。对上述的代码,有一种可能的情况是:先读a变量,再读x变量,再读b变量。对普通域而言,这样就是错误的情况(产生空指针)。但由于final域的读和对象引用的读不会发生重排序,所以不会出现问题。也就是可以确保:在读一个对象的final域之前,会先读包含这个final域的对象的引用
对final修饰的对象的成员域进行写操作(final域为引用类型)
在构造函数内对一个final修饰的对象的成员域的写入,与随后在在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作上不能被重排序
public class FinalReferenceDemo {
final int[] arrays;
private FinalReferenceDemo finalReferenceDemo;
public FinalReferenceDemo() {
arrays = new int[1]; //1
arrays[0] = 1; //2
}
public void writerOne() {
finalReferenceDemo = new FinalReferenceDemo(); //3
}
public void writerTwo() {
arrays[0] = 2; //4
}
public void reader() {
if (finalReferenceDemo != null) { //5
int temp = finalReferenceDemo.arrays[0]; //6
}
}
}
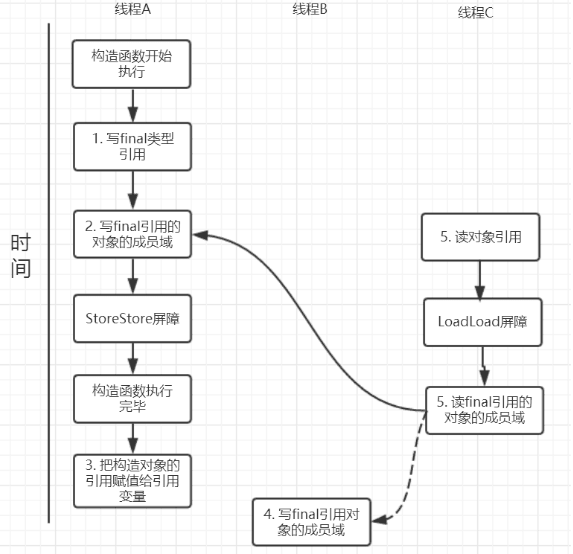
对final修饰的对象的成员域的读操作
JMM可以确保线程C至少能看到写线程A对final引用的对象的成员域的写入,即能看下arrays[0] = 1,而写线程B对数组元素的写入可能看到可能看不到。JMM不保证线程B的写入对线程C可见,线程B和线程C之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者volatile。(不是很有印象)
final引用从构造函数中溢出
考虑以下代码
public class FinalReferenceEscapeDemo {
private final int a;
private FinalReferenceEscapeDemo referenceDemo;
public FinalReferenceEscapeDemo() {
a = 1; //1
referenceDemo = this; //2
}
public void writer() {
new FinalReferenceEscapeDemo();
}
public void reader() {
if (referenceDemo != null) { //3
int temp = referenceDemo.a; //4
}
}
}
// 原文链接:https://pdai.tech/md/java/thread/java-thread-x-key-final.html
此时如果线程A开始执行writer方法然后执行构造函数, 由于构造方法中不存在数据一致性,所以1操作可能在2操作之后,那在2操作执行完毕且1操作还未执行的时候 ,这时候线程B执行reader方法(此时this引用溢出,对象还未构造完全后就未其他线程可见),检测referenceDemo对象不为空,然后访问其final成员,结果却为0,这就出现了问题。在构造函数返回前,被构造对象的引用不能被其他线程看见,因为此时的final域可能还没有被初始化。
实现Serlizable接口的类中UID是啥?
java序列化机制。简单来说,JAVA序列化的机制是通过 判断类的serialVersionUID来验证的版本一致的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID于本地相应实体类的serialVersionUID进行比较。如果相同说明是一致的,可以进行反序列化,否则会出现反序列化版本一致的异常,即是InvalidCastException
显示声明serialVersionUID可以避免对象不一致,
equals 和 hascode方法
为什么要重写
公式:
hashcode相等时内容不一定相等
equals相等时hashcode必须相等
hashmap 存入自定义类时引发的问题
想用表面一样的两把钥匙去开同一扇门的问题
hashcode方法如何重写
到底要比较什么属性或者对象
equals方法如何重写
hash值相同时,由于你 hashmap判断链表时,hash值会用equals 方法比较两个对象, 所以如果要开锁,这里就需要重写equals方法
Object类原生的equals方法就是判断地址,所以这里需要重写
String类的equals
if (this == anObject) {
//内存地址相等
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
//比较字符串长度
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
//逐一比较字符
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
AbstrackStringBuilder
构成
char[] value , int count
StringBuilder
static final long serialVersionUID = 4383685877147921099L;
区分 length() 和 capacity()
capacity大小并不是2的幂次方
默认16 默认预留的输入长度间隔,超过16则引起扩容
容量判断 ensureCapacityInternal(int minimumCapacity)
private void ensureCapacityInternal(int minimumCapacity) { // mini--- all words if (minimumCapacity - value.length > 0) { value = Arrays.copyOf(value, newCapacity(minimumCapacity)); } }扩容机制
private int newCapacity(int minCapacity) { // why add 2 ? //这里也就说明了为什么capacity为什么不是2的幂次方的问题了 int newCapacity = (value.length << 1) + 2; if (newCapacity - minCapacity < 0) { newCapacity = minCapacity; } return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0) ? hugeCapacity(minCapacity) : newCapacity; } private int hugeCapacity(int minCapacity) { if (Integer.MAX_VALUE - minCapacity < 0) { // overflow throw new OutOfMemoryError(); } return (minCapacity > MAX_ARRAY_SIZE) ? minCapacity : MAX_ARRAY_SIZE; }核心添加方法
//String 类下的 public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) { if (srcBegin < 0) { throw new StringIndexOutOfBoundsException(srcBegin); } if (srcEnd > value.length) { throw new StringIndexOutOfBoundsException(srcEnd); } if (srcBegin > srcEnd) { throw new StringIndexOutOfBoundsException(srcEnd - srcBegin); } //核心 System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); }
追问? 有了解过底层的arraycopy方法吗?
StringBuffer
结构: transient char[] toStringCache , static final long serialVersionUId
为何是线程安全的?
使用synchronized
接口、继承、泛型
如何看待接口和抽象类?
你怎么理解泛型?有什么作用?
向下转型和向上转型
将整个继承关系想像成由上至下
向上转型 子转父(包括接口) 丢失方法
向下转型 父转子 重新获得失去的方法
联想 :Android中findViewById中就是需要向下转型
自动拆箱和装箱
Integer a = 127;
Integer b = 127;
System.out.println(a == b);
//false
//字节码 比较时涉及到intValue方法
//new时涉及valueOf方法
public int intValue() {
return value;
}
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
//可以自行设置max的最大值
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
涉及到的静态内部类的知识
静态内部类只会在使用到该内部类时才会加载,否则是不会加载的,也就是只有使用到new Integer的valueOf方法时,才会加载该内部类
CAS
原理
若:内存位置的值 == 预期原值 -> 则赋予新值。通过while循环完成。
优点:不用进行用户态 内核态的切换
缺点:自旋时间不确定
增加版本控制: AtomicStampedReference,不但会判断原值,还会比较版本信息
泛型
为什么我们需要泛型?
没有泛型之前我们是怎么做到?我们可以通过Object存储任意的对象,然后使用时再强转成对应的类型就行了(但如果我们不清楚对象的类型,那么在转换时就kennel出现ClassCast Exception)
Java泛型Generics是JDK5中引入的新特性,提供了编译时类型安全检测机制,允许我们在编译时检测非法的类型数据结构。泛型的本质就是参数化类型,即所操作的数据类型被指定为一个参数。保证了类型安全,并消除了强制类型的转换
常用泛型标识 T E K V,泛型类不支持基本数据类型。为什么?
泛型类
在实例化类的时候指明泛型的具体类型。泛型类可以有多个泛型标识,不一定是1个或2个
同一泛型类,根据不同的数据类型创建对象,本质上还是同一个类型(getClass()相等)
泛型通配符:用?代替具体类型的实际参数,所以类型通配符是类型实 参而不是类型型参。通常结合上下限来限制泛型的实现类型
类型通配符的上限: <? extends XXXClass>
**类型通配符的下限:<? super xxxx> 要求该泛型的类型只能是实参类型或实参类型的父类型,下限不在创建泛型时使用 **
泛型类的继承
父类是泛型类:
- 子类是泛型类,子类是父类的泛型标识至少要包含父类的泛型标识
- 子类不是泛型类,父类要明确泛型的数据类型
泛型接口
- 实现类是泛型类,则实现了类的泛型标识要包含接口的泛型标识
- 实现类不是泛型类,实现类要明确接口定义的泛型
泛型方法
在调用方法的时候指明泛型的具体类型
语法: 修饰符 <T, E, ...> 返回值类型 方法名 (行参列表){}
其中<>指明了该方法是泛型方法,并指出其要用到的泛型标识
类型擦除
泛型信息只存在于代码编译阶段,进入JVM(生成字节码)之前与泛型相关的信息会被擦除掉
- 无限制类型擦除,泛型标识直接替换为Object(因为没有进行上下限的限制)
- 有限制类型擦除,
<T extends XXX>,按照上限类型进行类型擦除
桥接方法,在无泛型条件下保证接口和类的失信关系
泛型数组
可以声明带泛型的数组引用但不能直接创建带泛型的数组对象
ArrayList<String>[] arrayLists = new ArrayList<>[5];
这样就是错误的,编译报错 java: cannot create array with '<>'
ArrayList[] objects = new ArrayList[5];
ArrayList<String>[] arrayLists = objects;
ArrayList<Integer> objects1 = new ArrayList<>();
arrayLists[0] = objects1;
在较老版本中,以上代码可能编译不会报错,但实际运行若要使用到objects1中的值时则会抱数据转换类型的错,但目前自己的idea会抱这个错 jdk 1.8 341
ArrayList<String>[] arrayLists = new ArrayList[5];
比较稳妥的方法是这样,不要把原生数据类型暴露给外面,直接使用带有泛型规定的数组泛型对象,这样就能避免上述错误,这也是为什么java不支持直接创建泛型数组的原因
通过反射创建泛型数组
不能直接通过T[] data = new T[length]的方式创建数组(字节码层)
为什么不能通过上述方式创建数组呢?
这里的核心问题应该是是 T data = new T()无法通过编译,因为若没有上下限,则类型擦除时默认为Object,那这里你new的就是一个Object了。可以通过反射的方式创建
补充:
Object[] o = new String[10];
String typeName = o.getClass().getTypeName();
System.out.println(typeName);
// java.lang.String[]
o[0] = "123"
o[1] = new Object();
// throw ArrayStoreException
由于Java父子类型转换的限制,当第一行代码运行后,o对象其实便是String[]类型而非Object类型,运行上述代码会报错ArrayStoreException
如何通过泛型标识创建数组呢?使用反射
public class MyGenerics<T> {
T[] data;
public T[] getData() {
return data;
}
public MyGenerics(Class<T> t, int length) {
data = (T[]) Array.newInstance(t, length);
}
}
I/O操作
常见几大输入输出类
异常
Exception和Error关系
Exception和Error都可以被catch到
但不应在代码中catch error
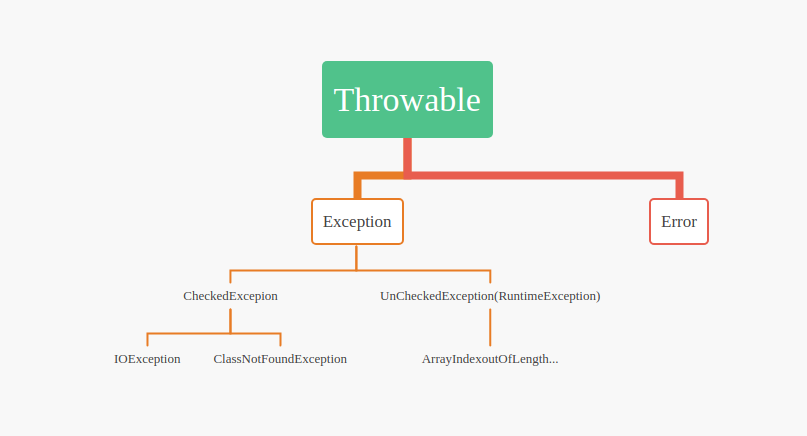
checkedException : 编译期异常,易处理,易出错的
面试问题
为什么0.1+0.2= 0.30000000004
short s1 = 1; s1 = s1 + 1;
HashSet内部如何实现?为什么要重写hashcode 和 equals方法?
try catch 中 return 会怎么样? 调用system.exit呢
为什么作为方法传参时,String 是不可变,但例如自定义类的引用 // 数组 是可变的呢
- 在我们进行传递时不管是值传递还是地址传递传递的都会copy一个副本进行传递而不是‘原件’。在引用数据类型中,副本与原件指向同一个地址时改变地址内部的值原件会受到影响,但是如果改变了副本指向的地址那么副本的一切变化于原件就没有关系了。
所以当 方法中的s发生改变时相当于将副本指向了新的地址于原件自然就没有关系了,方法外部的s没有变化也就解释的通了。
为什么String是不可变的
内部final修饰 ,s1 = s2 是允许的,仅改变指向的引用地址
是否可以改变value的值? 可以,反射
抽象类和接口的区别
抽象类 代码复用 相同的行为....
接口是对类的约束,强制要求不同的类有相同的行为
JDK 8新特性
**try catch return问题 **
如果在try、catch中 return ,finally 仍可执行,但finally后的语句不可执行